

Пошаговое объединение моделей и матричное квантование GGUF
⚠️ Я не эксперт в области машинного обучения. Эта статья представляет собой краткое изложение того, что я узнал о слиянии моделей из собственного опыта. Если вы заметите какие-либо ошибки, пожалуйста, укажите на них, и я исправлю их как можно скорее.
В этой статье я расскажу, что такое объединение моделей, и проведу вас через весь процесс объединения нескольких моделей, чтобы объединить их сильные стороны с помощью mergekit, а затем выполнить квантизацию файлов GGUF с помощью imatrix для использования в llama.cpp, Ollama и LM Studio. Надеюсь, эта статья станет полезной отправной точкой для новичков, желающих изучить объединение моделей.
0. Что такое слияние моделей
Короче говоря, слияние моделей — это метод, который позволяет объединить несколько моделей с разными сильными сторонами и возможностями, чтобы полученная модель унаследовала преимущества каждой из них. Например, слияние отредактированной (без цензуры) модели с моделью, настроенной на повествование, может создать модель, которая будет меньше отклонять запросы и при этом отлично справляться с повествованием.
Хотя объединённые модели обычно работают хуже, чем модели с тонкой настройкой или модели многозадачного обучения, их создание значительно проще и дешевле. При правильном сочетании и параметрах можно добиться отличных результатов. Более того, по мере совершенствования методов объединения ожидается повышение производительности объединённых моделей.
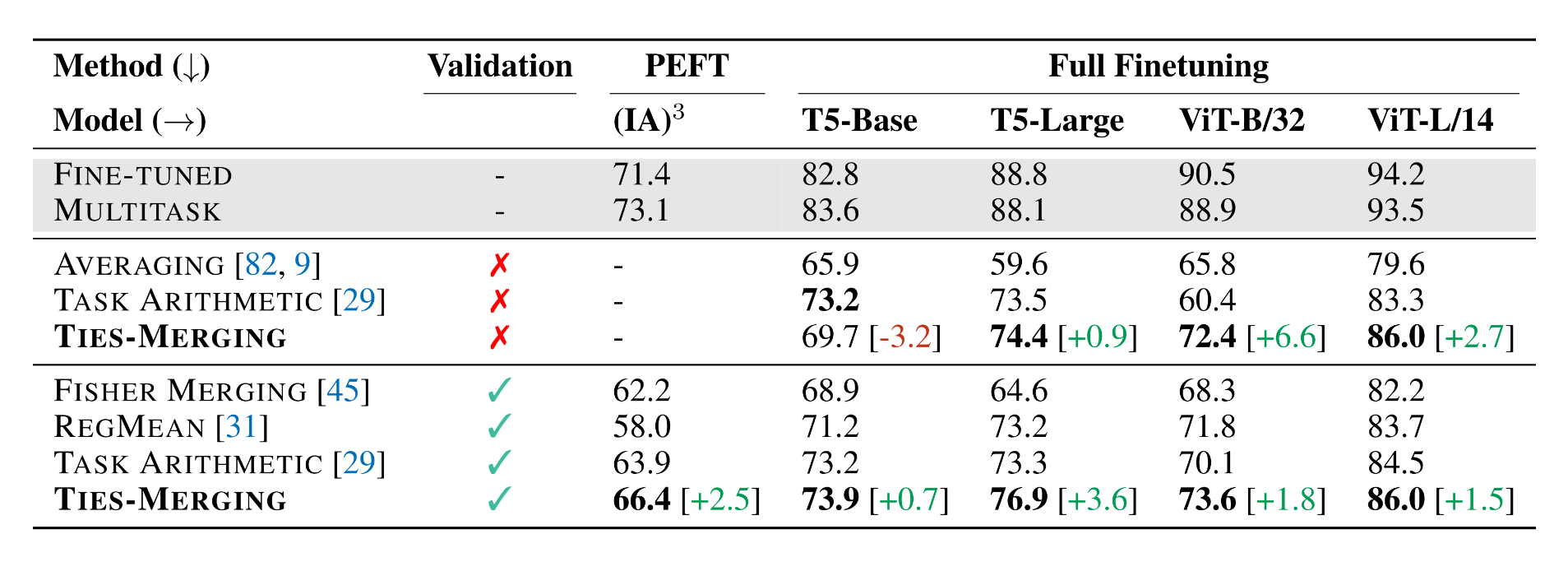 Рисунок 1. Сравнение методов объединения моделей при различных настройках тонкой настройки и модальностях (NLP и Vision) с использованием и без использования проверочного набора (источник).
Рисунок 1. Сравнение методов объединения моделей при различных настройках тонкой настройки и модальностях (NLP и Vision) с использованием и без использования проверочного набора (источник).
Объединение моделей основано на том, что различные «векторы задач (дельта-параметры)», представляющие разные возможности моделей, обычно близки к ортогональным.
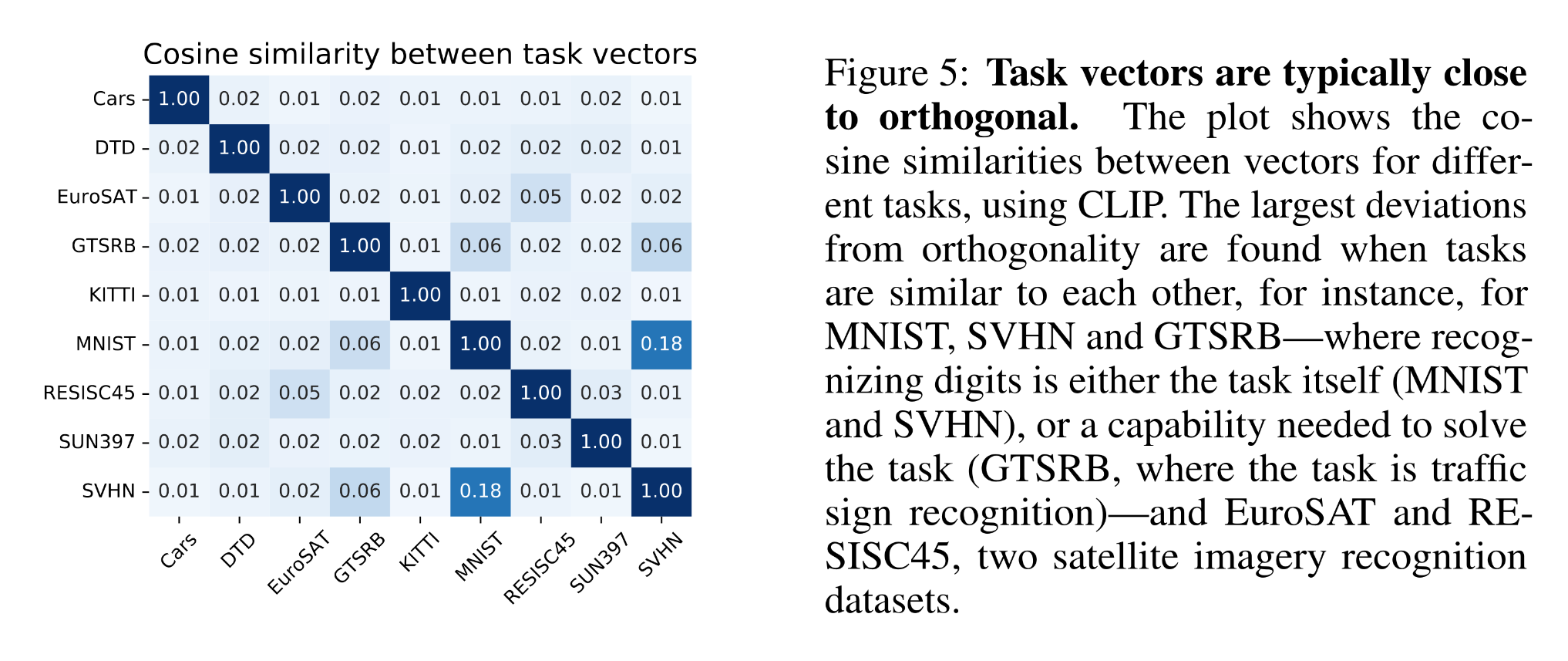 Рисунок 2. Косинусное сходство между векторами задач (источник)
Рисунок 2. Косинусное сходство между векторами задач (источник)
Чтобы узнать больше о технических аспектах объединения моделей, рекомендую прочитать статьи ниже. В оставшейся части статьи основное внимание будет уделено практическому процессу объединения моделей, а не теоретическим аспектам.
- Редактирование моделей с помощью Task Arithmetic
- TIES-Merging: устранение помех при объединении моделей
- Модельные супы: усреднение весов нескольких моделей с тонкой настройкой повышает точность без увеличения времени вывода
- Объединение моделей (Model Merging): целесообразность, распространённые методы и их особенности
1. Настройте среду
Для этой демонстрации я буду использовать Docker-контейнер Arch Linux в качестве среды для объединения моделей. Я выбрал Arch Linux, потому что в этом дистрибутиве проще всего компилировать такие программы, как llama.cpp, с поддержкой CUDA. Вы можете выбрать любой дистрибутив и настроить команды в соответствии с вашей средой. Я буду использовать mergekit для объединения моделей и Hugging Face в качестве репозитория моделей, поскольку это самые популярные варианты для этой задачи.
Установите зависимости сборки для mergekit и huggingface-cli:
|
|
Создайте виртуальную среду Python и установите mergekit и gguf-py. mergekit — это инструмент, который мы будем использовать для объединения моделей; gguf-py требуется скриптам llama.cpp для преобразования файлов моделей Safetensors в GGUF для llama.cpp, Ollama и LM Studio.
|
|
При желании вы можете включить в Hugging Face CLI использование hf_transfer для ускорения передачи данных:
|
|
Вы также можете записать этот параметр в /etc/environment, чтобы сделать его постоянным:
|
|
Вам также потребуется установить llama.cpp. Вы можете скачать и распаковать последние предварительно скомпилированные двоичные файлы или скомпилировать их самостоятельно. Поскольку я использую Arch Linux и графический процессор NVIDIA, я установлю пакет llama.cpp-cuda-f16 из пользовательского репозитория Arch (AUR) с помощью yay:
|
|
При компиляции llama.cpp-cuda-f16 в контейнере Arch Linux могут возникнуть проблемы, связанные с тем, что CMake не может найти инструментарий CUDA. Вы можете указать пути вручную, задав переменные среды CUDAToolkit_ROOT и CUDACXX . Команда yay также установит пакет cuda, который может конфликтовать с файлами драйверов, смонтированными при указании --gpus all в Docker. Вы можете использовать --overwrite='*' для принудительной перезаписи этих конфликтующих файлов.
|
|
2. Объединение моделей с помощью mergekit
Нам нужно написать файл конфигурации mergekit, в котором будет указано, какие модели мы хотим объединить, каким методом и с какими подробными параметрами.
Цель этой демонстрации — создать модель, которая хорошо справляется с повествованием и ролевыми играми, менее предвзята и реже отклоняет запросы пользователей. Исходя из этих требований, я выбрал для объединения следующие модели:
- nbeerbower/Llama-3.1-Nemotron-lorablated-70B: специализированная модель NVIDIA nvidia/Llama-3.1-Nemotron-70B-Instruct-HF с дополнительной тонкой настройкой LoRA для снижения количества отказов. Эта модель используется в качестве базовой и предоставляет основные возможности.
- SicariusSicariiStuff/Negative_LLAMA_70B: Llama 3.3 доработана для снижения положительного смещения модели.
- LatitudeGames/Wayfarer-Large-70B-Llama-3.3: Llama 3.3, доработанная для ролевых игр, позволяет создавать более мрачные, противоречивые и сложные сценарии.
- Sao10K/L3.3-70B-Euryale-v2.3: Llama 3.3, настроенная для сторителлинга и творчества.
- TheDrummer/Anubis-70B-v1: Llama 3.3, настроенная для сторителлинга и творчества.
В этой демонстрации мы не будем настраивать дополнительные параметры, такие как лямбда, вес или плотность. Разные методы объединения имеют свои преимущества и поддерживают разные параметры. Дополнительную информацию можно найти в документации mergekit и этой статье. Я выбрал метод объединения SCE, в основном потому, что он относительно новый. Вы также можете поэкспериментировать с другими методами объединения. Тип выходных данных — bfloat16, который обычно используется в моделях ИИ. Наконец, мы пишем файл конфигурации для mergekit:
|
|
Теперь вы можете приступить к объединению моделей с помощью приведенной ниже команды. Я назову модель Demo-LLaMA-70B. Вы также можете использовать такие флаги, как --gpu-rich или --cuda, чтобы ускорить объединение, если у вас достаточно видеопамяти.
|
|
Объединённая модель будет сохранена в формате Safetensors. Вы можете использовать совместимую среду выполнения, например vLLM, чтобы протестировать объединённую модель и убедиться, что она работает должным образом.
3. Преобразуйте модель в GGUF
После завершения объединения мы можем преобразовать модель, хранящуюся в формате Safetensors, в формат GGUF, чтобы конечные пользователи могли запускать её на llama.cpp, Ollama и LM Studio. В llama.cpp есть скрипт на Python, который может помочь с этим преобразованием.
Клонируйте репозиторий llama.cpp:
|
|
Запустите скрипт Python в llama.cpp, чтобы преобразовать модель из Safetensors в GGUF:
|
|
После преобразования вы можете протестировать модель, чтобы убедиться, что она работает (например, что в весовых коэффициентах нет значений NaN):
|
|
4. Вычислите матрицу важности (imatrix)
Матрица важности (imatrix) — это метод, который мы можем использовать для улучшения качества квантованной модели без увеличения её размера. Imatrix определяет, какие веса являются «значимыми», то есть оказывают большее влияние на результат. Увеличивая точность этих значимых весов, мы можем добиться лучших результатов квантования.
Нам нужно будет вычислить и откалибровать имитационную матрицу с помощью некоторых данных, чтобы она могла определять значимые веса. Для этой демонстрации я использую бартовски калибровочные данныеv3 в качестве данных для калибровки имитационной матрицы. Мы скачиваем и сохраняем их в файл:
|
|
Затем мы можем откалибровать imatrix с помощью инструмента llama-imatrix в llama.cpp. Вы можете установить параметр -ngl N для переноса N слоёв модели на графический процессор, чтобы ускорить калибровку.
|
|
Наличие быстрых графических процессоров с большим объемом видеопамяти, которые позволяют полностью перенести калибровку на графические процессоры, значительно облегчит этот этап. Например, без переноса на графический процессор этот этап занимает более пяти часов на центральном процессоре, а с переносом на четыре графических процессора A40 — всего 15 минут.
5. Квантование модели
Вы можете выбрать один из множества типов квантования. Чтобы определить, какой тип квантования использовать, обратитесь к этому руководству. На момент написания этой статьи я рекомендую выбирать самый большой тип квантования, который поместится в вашей видеопамяти, из следующих вариантов: IQ4_XS, Q4_K_M, Q5_K_M, Q6_K и BF16 (то есть без квантования, если оно подходит). Все доступные типы квантования можно посмотреть с помощью llama-quantize -h. Если вы решили не использовать imatrix, удалите аргумент --imatrix из команды.
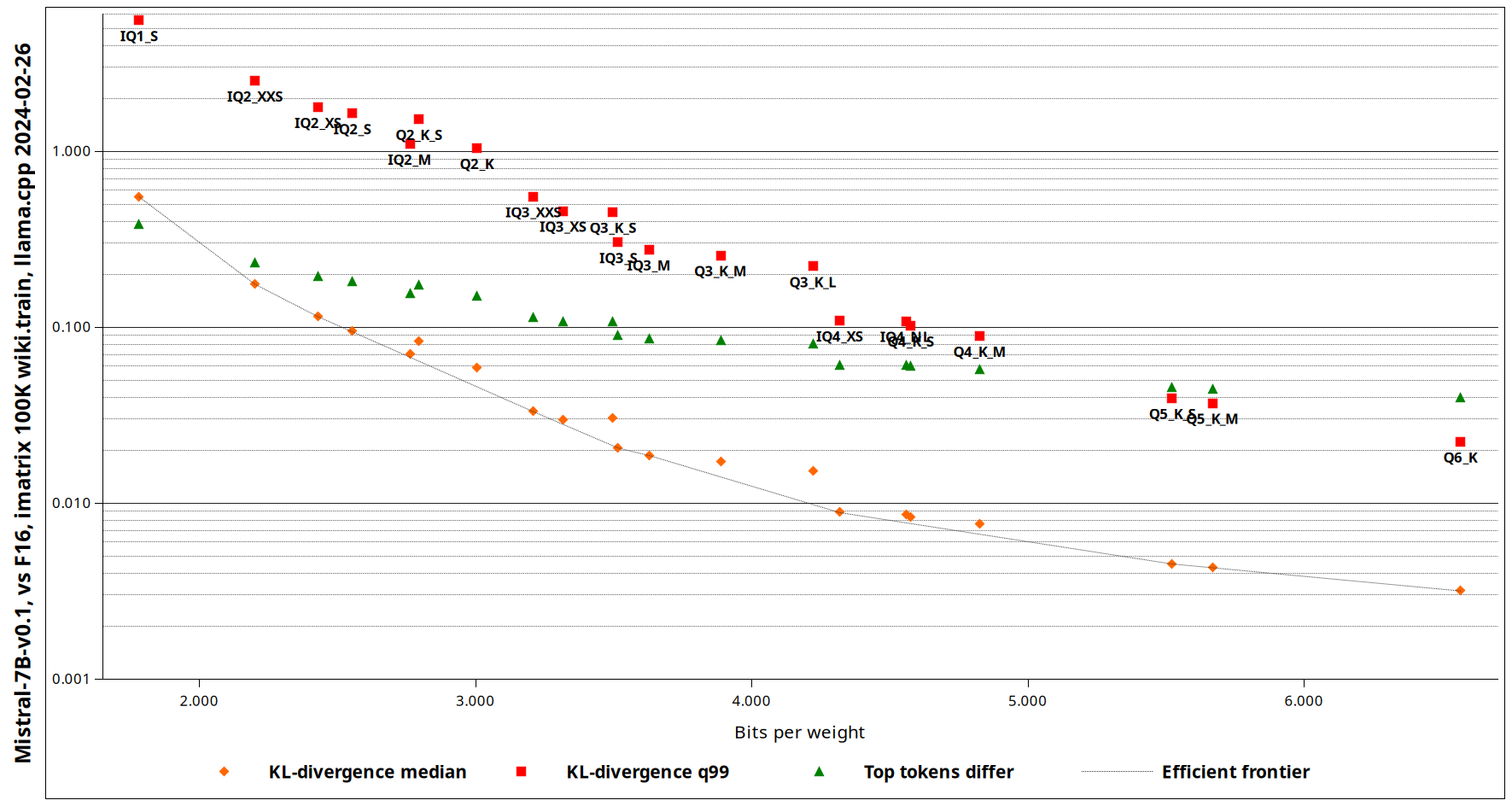 Рисунок 3. Сравнение KV-дивергенции между различными типами квантования, поддерживаемыми llama.cpp (исходный код)
Рисунок 3. Сравнение KV-дивергенции между различными типами квантования, поддерживаемыми llama.cpp (исходный код)
Определившись с типом квантования, выполните приведенную ниже команду для квантования модели.
|
|
Поскольку такие платформы, как Hugging Face, ограничивают максимальный размер отдельных файлов, мы можем использовать llama-gguf-split для разделения больших файлов GGUF на несколько файлов меньшего размера. Максимальный размер одного файла в Hugging Face составляет 50 ГиБ, поэтому мы можем разделить модель bfloat16, размер которой, скорее всего, превышает 50 ГиБ, на несколько файлов меньшего размера, каждый из которых будет не больше 50 ГиБ.
|
|
6. Загрузите файлы модели
Наконец, вы можете загрузить файл в Hugging Face для хранения и публикации.
С помощью приведенных ниже команд вы можете загрузить файлы модели Safetensors в репозиторий Hugging Face. Публикация файлов Safetensors позволит другим пользователям легко объединять вашу модель с другими моделями или настраивать ее.
|
|
С помощью приведенных ниже команд вы можете загрузить файлы модели GGUF в репозиторий Hugging Face. Публикация файлов GGUF позволит конечным пользователям легко запускать вашу модель в распространенных системах логического вывода, таких как llama.cpp, Ollama и LM Studio.
|
|
Дополнительную информацию о том, как использовать инструмент huggingface-cli, можно найти на странице документации.
7. Послесловие
Объединение моделей — это экономичный, но при этом эффективный метод, который позволяет повысить производительность модели за счёт объединения сильных сторон нескольких моделей. Это эффективный способ улучшить результаты без необходимости в дорогостоящем предварительном обучении или тонкой настройке. Я с удовольствием экспериментировал с различными вариантами объединения моделей и тестировал их в группах Telegram с помощью Tellama. Надеюсь, эта статья была для вас информативной и полезной и вдохновила вас на собственные эксперименты с объединением моделей.
Отправить ответ
Для отправки комментария вам необходимо авторизоваться.